
Cette page décrit les différentes étapes du processus de constitution de la ressource, de la transcription à sa normalisation puis à l'annotation.
Ces étapes sont illustrées dans le schéma ci-dessous.
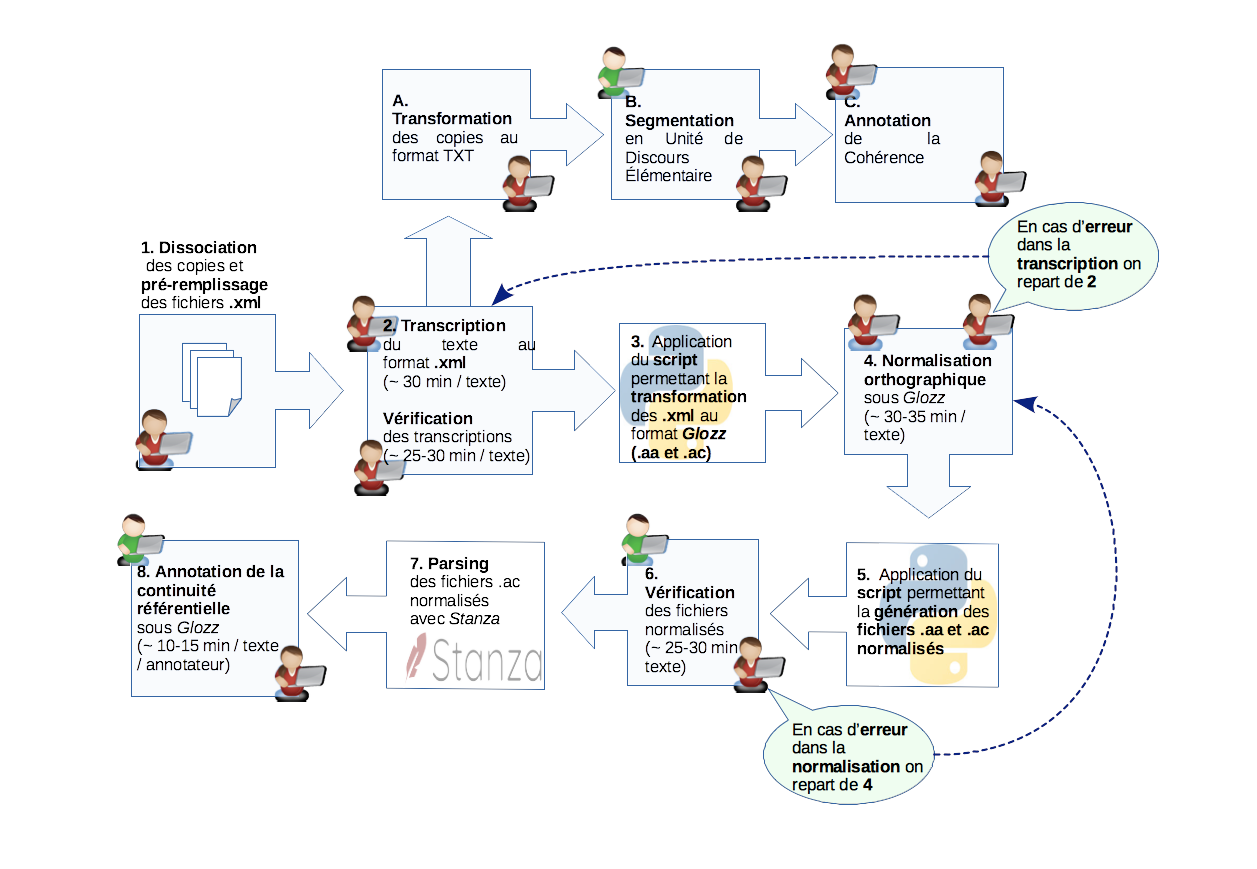
Les étapes préliminaires sont les suivantes :
A partir de là, deux processus parallèles d'annotation ont été mis en place :
1) Pour l'annotation de la continuité référentielle:
L'originalité du corpus RésolCo réside dans le fait que les textes produits répondent tous à une même consigne d'écriture.
Celle-ci est une tâche-problème imposant aux élèves la résolution de problèmes de cohésion textuelle (Garcia-Debanc et Bonnemaison, 2014 ; Garcia-Debanc et Bras, 2016).
L'objectif de cette consigne, fournie ci-dessous et accompagnée d'un texte réalisé par un élève de CE2, est de provoquer chez le scripteur la mise en oeuvre de stratégies de résolution des problèmes de cohérence soulevés par l'intégration de trois phrases dans un récit.
|
Consigne : Racontez une histoire dans laquelle vous insérerez, séparément et dans l'ordre donné, les trois phrases suivantes :
Vous pouvez découper les bandelettes contenant les phrases ci-dessous ou bien recopier chaque phrase avec soin à l'identique de celles qui vous sont données. |
Ci-dessous un exemple de texte récolté en 2016 dans une classe de CE2.  . . |
Les trois phrases impliquent des stratégies discursives variées, amenant le scripteur à gérer plusieurs continuités référentielles et planifier son discours afin d'assurer la cohérence de son texte (Garcia-Debanc et al. 2017).
Il est possible de contribuer à la récolte des textes en utilisant la consigne et les documents nécessaires à la collecte des textes. Cette consigne et ces documents sont disponibles au format .pdf en suivant le lien : documents pour la récolte des textes d'élèves.
Afin de transformer les textes en une ressource exploitable par la communauté scientifique, et y appliquer des méthodes de linguistique de corpus et de TAL, il est nécessaire de passer par une étape de transcription des scans de textes. Le format choisi pour la transcription est le format XML, selon la norme TEI-P5.
Toute transcription est anonymisée et assortie de métadonnées fournissant des informations sur la collecte et la numérisation du texte, sur les conditions d'écriture et sur l'école qui a participé à la récolte des textes. La vérification est effectuée par un correcteur différent du transcripteur.
Pour ce qui concerne le corps du texte, l'objectif de la transcription est de reproduire le plus fidèlement possible le texte du scripteur. Afin d'obtenir une reproduction fidèle, la mise en page ligne par ligne est renseignée ainsi que toute trace du processus d'écriture comme les ratures, les ajouts, les soulignements, etc. Aucune erreur d'orthographe n'est corrigée lors de la transcription.
Pour plus de détails concernant les éléments transcrits et les balises utilisées vous pouvez consulter :
Cette phase consiste en un étiquetage des erreurs d'orthographe grâce à l'interface d'annotation Glozz (Widlöcher A. and Mathet Y., 2009).
Pour ce qui concerne l'annotation des erreurs d'orthographe, il a été décidé de ne pas classer les erreurs. En effet, la catégorisation des erreurs orthographiques sera effectuée par les experts du projet E-Calm qui travaillent sur l'orthographe.
La normalisation du corpus RésolCo est effectuée par des annotateurs francophones.
Lorsqu'ils ont un doute, les annotateurs peuvent indiquer une incertitude concernant la détection et/ou la correction de l'erreur.
Si plusieurs solutions de correction sont possibles, elles sont indiquées.
Toute normalisation est vérifiée par une personne différente de celle qui a annoté le texte.
Pour plus de détails concernant les éléments normalisés et les décisions prises vous pouvez consulter :
L'étude de la cohérence discursive dans les écrits d'élèves et d'étudiants est au coeur du projet E-calm. Afin d'analyser l'évolution de la cohérence dans les textes entre l'école primaire et le collège, une annotation de la cohérence a été réalisée sur des textes d'élèves de CE2, 6ème et 3ème. Elle comporte une segmentation des textes en Unités de Discours Elémentaires et une annotation en Relations de Discours accompagnée d'une annotation des problèmes de cohérence rencontrés.
Pour obtenir le corpus annoté veuillez consulter la page Téléchargement
L'étude de la cohérence discursive dans les écrits d'élèves et d'étudiants est une des tâches principales au coeur du projet E-calm. Afin d'obtenir un aperçu de la maîtrise et de l'évolution de cette compétence, l'annotation de la continuité référentielle vise à décrire de façon exhaustive et systématique les formes linguistiques utilisées pour construire la référence dans les textes.
Une annotation de chaque "maillon" des chaînes référentielles correspondant aux trois référents humains de la consigne a été effectuée pour les textes normalisés grâce à l'interface d'annotation Glozz (Widlöcher A. and Mathet Y., 2009).
L'alignement de ces textes annotés avec les textes parsés avec Stanza permet de récupérer les informations morpho-syntaxiques afin de réaliser une analyse plus fine des chaines.
Pour plus de détails concernant l'annotation ou pour explorer le corpus normalisé et annoté veuillez consulter la page Exploration CR
Site développé par Y. Bard, S. Federzoni et L.M. Ho-Dac (contact).
