Exploration du corpus transcrit
Cette page vous permet d'explorer le corpus RésolCo via le tableau d'interrogation proposé ci-dessous. Ce tableau permet une exploration et une sélection des textes du corpus dans leur version brute (images et transcriptions) et annotée en traces d'écritures (ratures, insertions).
Pour accéder à la visualisation des textes (images et transcription), cliquer sur l'identifiant dans la colonne ID.
Filtrer les textes
- ID (identifiant) :
permet de filtrer les textes par année, niveau scolaire, classe, devoir, version... (Voir explication du codage des identifiants ci-contre).
Par exemple en écrivant "CE2" dans la barre de recherche, seuls les textes récoltés dans des classes de CE2 seront sélectionnés
- Nb erreurs : le nombre minimum et maximum d'erreurs qui ont donné lieu à une normalisation orthographique
- Nb ratures : le nombre minimum et maximum de ratures (traces de révision par insertion et/ou suppression de texte) encodées lors de la transcription
- Texte original donne accès aux versions originales des textes ainsi qu'à une recherche par formes présentes dans le texte. Par exemple la requête "il étais" permet une sélection des textes contenant cette chaine de caractères
- Texte normalisé donne accès aux versions normalisées orthographiquement des textes ainsi qu'à une recherche par formes présentes dans le texte. Par exemple la requête "il était" permet une sélection des textes contenant cette chaine de caractères
|
Explication des identifiants des fichiers
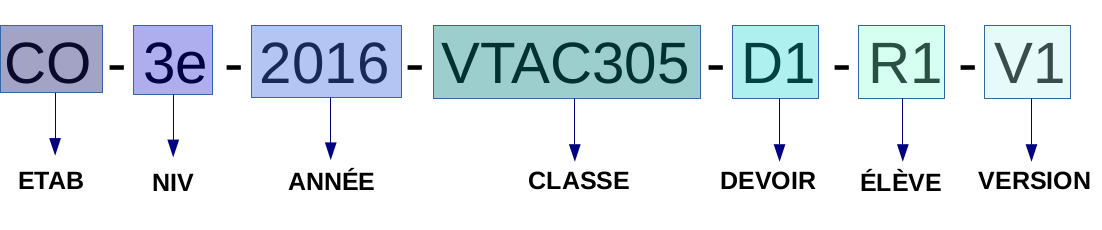
- ETAB : le type d'établissement EC (école) ; CO (collège) ; UN (université)
- NIV : le niveau scolaire
- ANNÉE : l'année scolaire de production (un texte écrit le 3 mars 2015 compte pour l'année scolaire 2014)
- CLASSE : l'identifiant de la classe
- DEVOIR : l'identifiant du devoir
- ÉLÈVE : l'identifiant de l'élève précédé d'une indication sur la provenance du corpus.
La provenance est "R" (pour corpus RésolCo) suivi du numéro de l'élève
- VERSION : V1, V2 ...
|
Le tableau d'interrogation du corpus a été créé à l'aide de l'outil Tabulator.
